Getting started with SRE - implementing SLAs, SLIs, and SLOs
TweetShobhit, Prashant and I wrote this document for observability whitepaper written by CNCF’s tag-observability group.
Purpose
Implementing these SRE metrics lets you measure service quality and customer happiness objectively. More so over, it provides a common set of terminologies between different functions like business, product and engineering within an org. Engineering time is a scarce resource within any organisation but everyone feels like their problem is a burning problem. But SRE metrics make such conversations more data driven. Everyone understands the business consequences of breaching SLOs. While solving internal conflicts, it also makes you more customer obsessed by providing meaningful abstractions that enable meaningful and actionable alerting.
Definitions
Before we deep dive in the implementation details, we should get the definitions clear as they can be fairly confusing and sometimes be used interchangeably.
- Service Level Indicator (SLI): An SLI is a service level indicator—a carefully defined quantitative measure of some aspect of the level of service that is provided.
- Service Level Objective (SLO): An SLO is a service level objective: objective for how often you can afford for it to fail. a target value or range of values for a service level that is measured by an SLI
- Service Level Agreement (SLA): a business contract that includes consequences of violating the SLO. This is a targeted percentage
- Error budget: tolerance for failed events over a period of time determined by SLO. This is 100% minus the SLO
Implementation
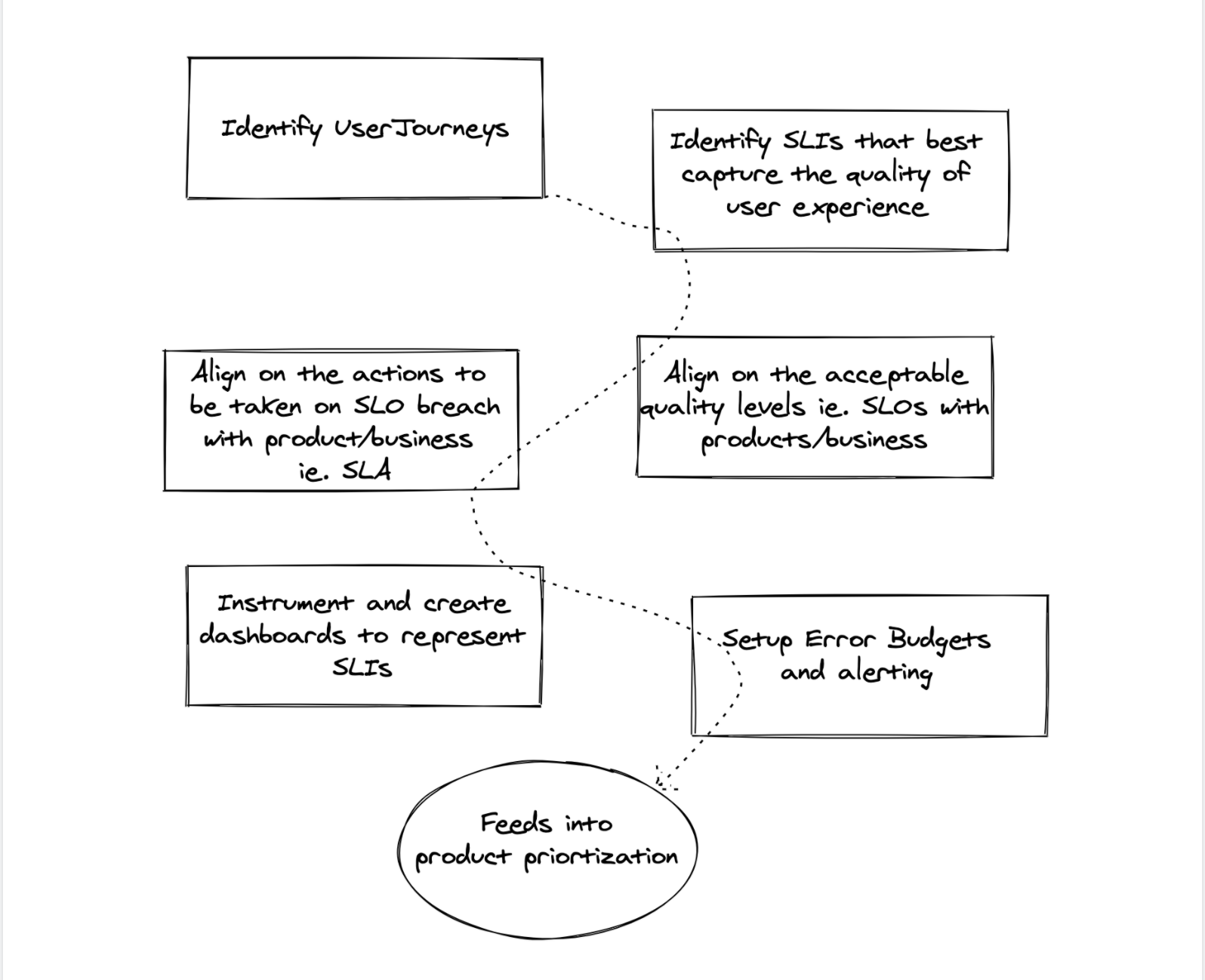
In order for a proposed SLO to be useful and effective, you will need to get all stakeholders to agree to it. The product managers have to agree that this threshold is good enough for users—performance below this value is unacceptably low and worth spending engineering time to fix. The product developers need to agree that if the error budget has been exhausted, they will take some steps to reduce risk to users until the service is back in budget. The team responsible for the production environment who are tasked with defending this SLO have agreed that it is defensible without Herculean effort, excessive toil, and burnout—all of which are damaging to the long-term health of the team and service.